ETL ย่อมาจาก Extract, Transformation, และ Load พูดง่ายๆ คือ การคัดลอกข้อมูลจากที่หนึ่งไปยังอีกที่หนึ่ง
Extract
Transform : เป็นการแปลงข้อมูลเป็นรูปแบบ หรือเพิ่มเติมข้อมูลที่ต้องการ
Load
ETL สามารถแบ่งได้เป็น 2 ประเภท ขึ้นกับโครงสร้างที่วางไว้
Traditional ETL
เมื่อคิดย้อนกลับไป ข้อมูลต่าง ๆ นิยมเก็บไว้ที่ operational databases , ไฟล์ และคลังข้อมูล โดยข้อมูลถูกย้ายระหว่างที่เก็บข้อมูลวันละ 2-3 ครั้ง เครื่องมือ ETL และสคริปต์ ถูกเชื่อมต่อกับแหล่งข้อมูลแบบชั่วคราว ขณะที่ ETL ทำงาน

Traditional ETL workflow
โครงสร้างของเครื่องมือ ETL นี้ซับซ้อน และจัดการได้ยาก ข้อเสียของสถาปัตยกรรม traditional ETL- กระบวนการระหว่างฐานข้อมูล ไฟล์ และคลังข้อมูลทำงานในแบบ batch
- ปัจจุบันบริษัทส่วนใหญ่มักจะวิเคราะห์ และดำเนินการกับข้อมูลแบบ real-time อย่างไรก็ตามเครื่องมือแบบดั้งเดิมไม่ได้ถูกออกแบบมาเพื่อประมวลผล log ข้อมูลเซ็นเซอร์ ข้อมูลเมทริก ฯลฯ
- การสร้างแบบจำลองข้อมูลสำหรับโดเมนที่มีขนาดใหญ่มาก ต้องการ global schema
- กระบวนการ ETL แบบดั้งเดิมทำงานช้า กินเวลานาน และใช้ทรัพยากรจำนวนมหาศาล
- สถาปัตยกรรมแบบดั้งเดิมมุ่งเน้นที่เทคโนโลยีเท่านั้น ดังนั้นเทคโนโลยีใหม่จึงถูกแนะนำการใช้งาน และเครื่องมือที่ต้องเขียนขึ้นตั้งแต่เริ่มต้นเพื่อเชื่อมต่อ
สถานะปัจจุบันของ ETL
โลกข้อมูลสมัยใหม่ และการใช้งานมีการเปลี่ยนแปลงไปอย่างมากเมื่อเทียบกับทศวรรษที่ผ่านมา มีช่องว่างที่เกิดจากกระบวนการ ETL แบบดั้งเดิม เมื่อประมวลผลข้อมูลที่ทันสมัย เหตุผลหลักบางประการ คือ
- กระบวนการของข้อมูลสมัยใหม่ มักจะรวมถึงข้อมูลการสตรีมแบบเรียลไทม์ และองค์กรต้องการกระบวนการข้อมูลเชิงลึกแบบเรียลไทม์
- ระบบต้องรองรับการทำงาน ETL แบบเรียลไทม์ที่ไม่มีการทำงานแบบ batch และรับมือกับข้อมูลปริมาณมากในระบบที่ขยายได้
- ขณะนี้ฐานข้อมูลเซิร์ฟเวอร์เดียวบางส่วนจะถูกแทนที่ด้วยแพลตฟอร์มข้อมูลแบบกระจาย (เช่น Cassandra, MongoDB, Elasticsearch, แอป SSAS), message brokers (เช่น Kafka, ActiveMQ ฯลฯ) และ endpoint ประเภทอื่น ๆ
- ระบบควรมีความสามารถในการปลั๊กอินแหล่งที่มาเพิ่มเติม หรือจัดการวิธีการเชื่อมต่อได้
- การประมวลผลข้อมูลซ้ำ เนื่องจากต้องลดสถาปัตยกรรมเฉพาะกิจ
- เปลี่ยนเทคโนโลยีการจับข้อมูลที่ใช้กับ ETL แบบดั้งเดิมจะต้องมีการเชื่อมต่อที่ เพื่อสนับสนุนการทำงานแบบดั้งเดิม
- มีแหล่งข้อมูลต่างกัน และควรดูการบำรุงรักษาตามข้อกำหนดใหม่
- แหล่งที่มา และ endpoint เป้าหมายควรถูกแยกออกจากขั้นตอนทางธุรกิจ ชั้นข้อมูล mapper ควรอนุญาตให้แหล่งที่มา และ endpoint สามารถเชื่อมต่อโดยไม่กระทบต่อการเปลี่ยนแปลง

Data mapping layer
- การรับข้อมูลควรมีมาตรฐานก่อนเปลี่ยนแปลง (หรือดำเนินการตามกฎเกณฑ์ทางธุรกิจ)
- ข้อมูลควรถูกแปลงเป็นรูปแบบเฉพาะหลังจากการแปลง และก่อนที่จะเผยแพร่ไปยัง endpoint
- Data cleansing ไม่ใช่กระบวนการเดียวที่กำหนดไว้ในการเปลี่ยนแปลงในโลกสมัยใหม่ มีข้อกำหนดทางธุรกิจมากมายที่องค์การต้องปฏิบัติตาม
- การประมวลผลข้อมูลปัจจุบันควรใช้ตัวกรอง การรวม ลำดับ รูปแบบและกลไกที่สมบูรณ์ เพื่อดำเนินการตามกฎเกณฑ์ทางธุรกิจที่ซับซ้อน

Data processing workflow
Streaming ETL to the Rescue
ข้อมูล คือ เชื้อเพลิงที่ขับเคลื่อนองค์กร เนื่องจากความต้องการข้อมูลใหม่ ระบบดั้งเดิมส่วนใหญ่ยังคงใช้งานได้ในองค์กรส่วนใหญ่ และใช้ฐานข้อมูลและระบบไฟล์ องค์กรเดียวกันกำลังพยายามที่จะย้ายไปสู่ระบบใหม่ และเทคโนโลยีใหม่ เทคโนโลยีเหล่านี้มีความสามารถในการรองรับการเติบโตของข้อมูลขนาดใหญ่ และอัตราการส่งข้อมูลสูง อาทิเช่น 10,000 รายการต่อวินาที เช่น Kafka, ActiveMQ เป็นต้น
การทำงานร่วมกับสถาปัตยกรรมสตรีมมิ่ง ETL องค์กรไม่ต้องออกแบบ และใช้สถาปัตยกรรมที่ซับซ้อนเพื่อเติมเต็มช่องว่างระหว่างระบบดั้งเดิม และระบบปัจจุบัน สถาปัตยกรรมสตรีมมิ่ง ETL สามารถขยายและจัดการได้ในขณะที่ปริมาณข้อมูลเพิ่มมากขึ้นแบบเรียลไทม์ รวมถึงความหลากหลายของโครงสร้างที่พัฒนาขึ้นด้วย
Source sink โมเดล ได้นำเสนอโดยการแยก extract และ loading ออกจาก transform ทำให้ระบบสามารถทำงานร่วมกับเทคโนโลยี และฟังก์ชันใหม่ได้ การทำงานนี้สามารถทำได้ผ่านหลายระบบ เช่น Apache Kafka (กับ KSQL), Talend, Hazelcast, Striim และ WSO2 Streaming Integrator (กับ Siddhi IO)
Model ETL function
อย่างที่เขียนไว้ก่อนหน้านี้ ระบบดังเดิมมักจะถ่ายโอนข้อมูลทั้งหมด ไปยังฐานข้อมูล และระบบไฟล์ที่พร้อมใช้งานสำหรับการประมวลผลเป็นชุด (batch) สถานการณ์นี้บอกได้ว่าแหล่งที่มาของเหตุการณ์แบบดังเดิม เช่น ไฟล์ และ Change Data Capture (CDC) ได้ถูกรวมเข้ากับแพลตฟอร์มสตรีมมิ่งแบบใหม่อย่างไร
ลองมาพิจารณาสถานการณ์จริงในโรงงานผลิตที่มีฟังก์ชันต่อไปนี้
ระบบแบบดั้งเดิม
- ถ่ายโอนข้อมูลการผลิตทั้งหมดลงในระบบไฟล์ และฐานข้อมูลที่มี schema ที่แตกต่างกัน
- กระบวนการถ่ายโอนข้อมูลแบบรายชั่วโมง หรือรายวัน
- ประมวลผลเหตุการณ์ที่ได้รับจาก CDC
- ประมวลผลศูนย์กลางข้อมูลเหตุการณ์ (event-centric data) ที่ได้จากระบบใหม่ (ผ่าน HTTP)
- ส่งข้อมูลเหตุการณ์ที่ประมวลผลไปยังหลายปลายทาง
- ตรวจสอบสต็อกปัจจุบัน และส่งการแจ้งเตือนเมื่อมีต้องการสต็อกเพิ่ม
- ดูการวิเคราะห์โดยใช้หมายเลขสต็อก
ในเครื่องมือ ETL แบบดั้งเดิม
- ตรรกะการประมวลผล ETL ถูกดำเนินการซ้ำ ในเหตุการณ์ต่อไปนี้
- สำหรับแต่ละไฟล์ และฐานข้อมูลที่มี schema แตกต่างกัน
- เมื่อจำนวนของเป้าหมาย หรือปลายทางเพิ่มขึ้น
- ตรรกะทางธุรกิจซ้ำ ๆ ทำให้ยากต่อการจัดการ และขยาย
- การคำนวณกระบวนการซ้ำ ๆ ที่ต้องดึงข้อมูลมาวิเคราะห์ และตรวจสอบ
แฟลตฟอร์มสถาปัตยกรรมสตรีมมิ่งได้เข้ามาแก้ไขปัญหา ETL สมัยใหม่ได้อย่างไร
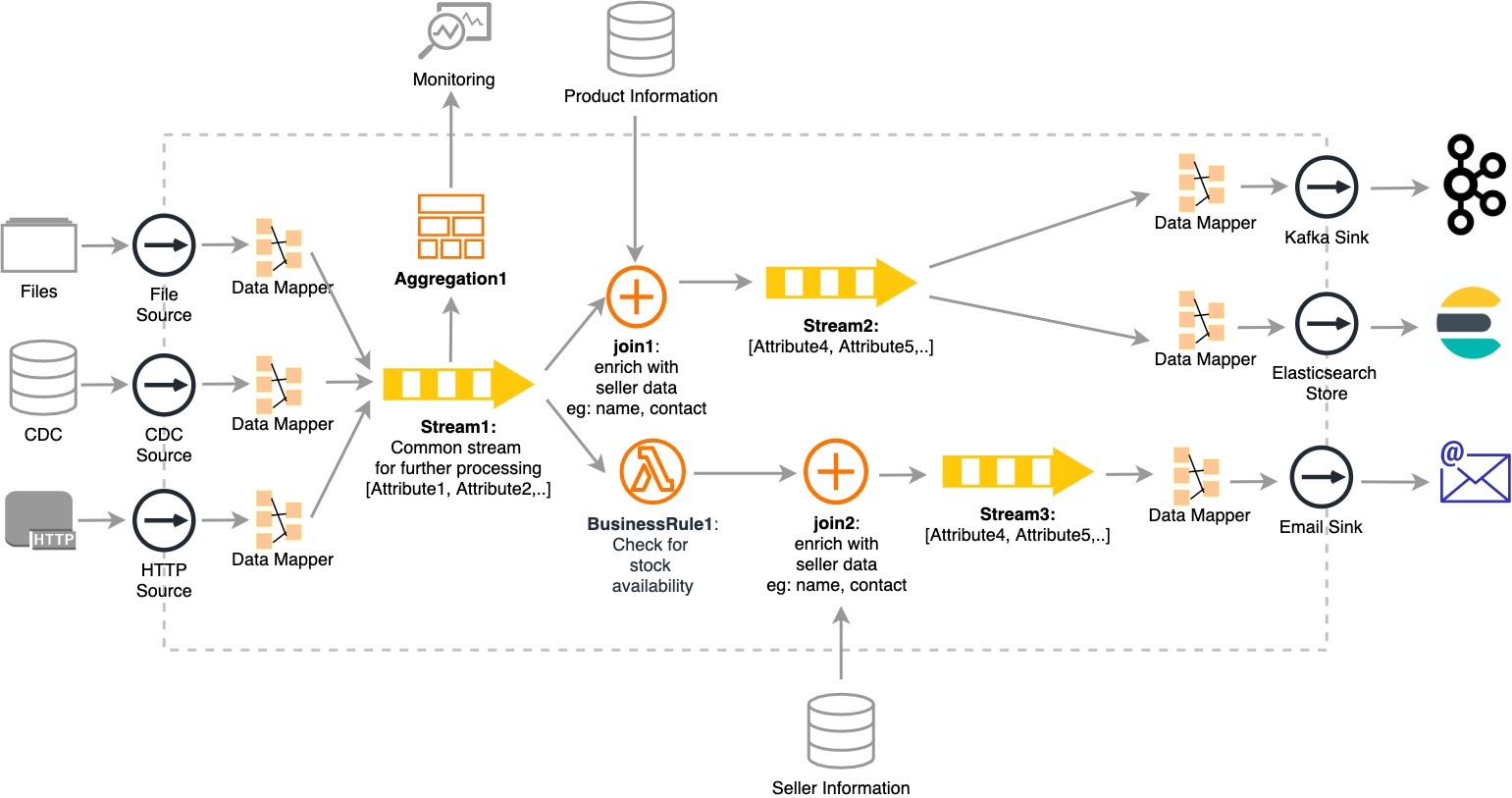
Modern streaming platform workflow
- แหล่งที่มา (เช่น ไฟล์, CDC, HTTP) และเป้าหมายปลายทาง (เช่น Kafka, Elasticsearch, อีเมล) ถูกแยกออกจากการประมวลผล :
- Sink, Source และ Store APIs เชื่อมต่อกับแหล่งข้อมูลจำนวนมาก
- แม้ว่าจะมีความแตกต่างของ schema ข้อมูล ทั้งต้นทาง ชั้นเก็บข้อมูล (เช่น data mapper) และสตรีมมิ่ง SQL (เช่น Query1) จะแปลงเหตุการณ์ที่ได้รับผ่านหลากหลายแหล่งที่เป็นข้อกำหนดสตรีมทั่วไป (Stream1) เพื่อการประมวลเพิ่มเติม
- สถาปัตยกรรมสตรีมมิ่งแพลตฟอร์มเชื่อมต่อแหล่งที่มาแบบดั้งเดิม เช่น ไฟล์ และ CDC รวมถึงแหล่งที่มาสมัยใหม่อีกหลายประเภทด้วย อย่างเช่น HTTP
- เหตุการณ์ที่เกิดขึ้นจากระบบดั้งเดิม และระบบสมัยใหม่จะได้รับการวิเคราะห์ในขั้นตอนเดียวกัน
- การรวม (aggregation) (เช่น การรวม1) ถูกประมวลผลสำหรับส่วนที่สำคัญภายในไม่กี่นาที ไม่กี่ชั่วโมง ฯลฯ
- ข้อมูลถูกสรุปโดยไม่ต้องประมวลผล และสรุปชุดข้อมูลทั้งหมดได้เมื่อต้องการ แอพพลิเคชั่น และเครื่องมือการแสดงผล และตรวจสอบสามารถเข้าถึงข้อมูลสรุปได้ผ่านทาง APIs
- จะหนึ่งหรือหลายตรรกะทางธุรกิจ (เช่น BusinessRule1) สามารถเพิ่ม และเปลี่ยนแปลงได้อย่างไม่สะดุด
- การเพิ่มตรรกะสามารถทำได้โดยไม่กระทบกับการทำงานเดิมที่มีอยู่แล้ว ดังเช่นตัวอย่างนี้ ข้อความอีเมลจะถูกกระตุ้น (trigger) เมื่อระดับความรุนแรงถึงจุดวิกฤตตามที่กำหนดไว้ใน BusinessRule1
คุณสามารถอ้างถึงสตรีมมิ่ง ETL นี้ด้วยหัวข้อ WSO2 Streaming Integrator ถึงวิธีที่ WOS2 Streaming Integrator ได้เตรียมแนวทางการทำงานสำหรับ ETL ที่ซับซ้อนเอาไว้
Cr: DZone



